

Introduction to Embedding and GPT
In the vast realm of artificial intelligence (AI) and machine learning, a foundational truth stands firm: these systems thrive on numbers. While we live in a world filled with rich nuances and myriad forms of data, at their core, AI models recognise and understand numeric representations.
Rewinding to 2019, during my pursuit of “100 Days of Machine Learning,” I found that a staggering 80% of the effort was invested not in modeling, but in data wrangling – sifting through, cleaning, and transforming raw data into a structured format ready for machine learning consumption.
So, how do we bridge the gap between the varied forms of organisational data and the number-crunching prowess of AI models? Enter the concept of “embedding.” This post will delve into the intricate world of embeddings and how they can be harnessed to unlock the capabilities of advanced models like GPT, tailored specifically for an organisation’s unique data.
Understanding Neural Networks
Next, what is a neural network? It is a computational model inspired by the human brain’s structure. It consists of interconnected nodes (analogous to neurons) that process information in layers. Neural networks are a subset of machine learning (ML), a branch of artificial intelligence (AI).
In the AI/ML landscape, neural networks are especially popular for tasks like image and speech recognition. When applied to language tasks, such as translation or sentiment analysis, it falls under the domain of Natural Language Processing (NLP).
Demystifying Embeddings
Embedding is associated with NLP and is a technique where words or phrases are converted into vectors of numbers, allowing the computer to understand and process language. By representing words as vectors, we can capture their meaning and relationship with other words. As I said, this is crucial for tasks like text analysis, translation, and sentiment detection. Embeddings make it possible for machines to grasp the nuances of human language.
Embedding is mapping discrete or categorical variables to a vector of continuous numbers …
What does that actually mean you ask?! 🙂
Well, a discrete or categorical variable can take on one of a limited set of values, like days of the week or colours of a rainbow. It’s like choosing a flavour at an ice cream shop; you pick one specific option from the available choices.
And “a vector of continuous numbers”?!
I have got you … 🙂
Think of a row of water bottles lined up on a table. Each bottle can be filled to any level, not just full or empty. One might be half-full, another 1/4 full, and another almost to the top. A vector of continuous numbers is like a list of the water levels in each bottle. It captures the exact amount in each bottle, even if it’s somewhere in between full and empty.
Ok, so we have a collection of numbers but what does that mean with regard to embedding?
Imagine you visit a vast library with millions of books. Each book represents a unique category or topic. Now, if you had to describe each book’s content, it would be a lengthy process. Instead, what if you could summarise each book with a small set of keywords or a short summary? That would make things much more manageable!
So, each book represents a discrete or categorical variable. The set of keywords or short summaries for each book represents the embedding – a simpler, condensed representation of the book. Instead of describing the entire book, you use a vector (a list) of continuous numbers (the keywords or summary) to represent it; the genre is a simple example.
When we talk about neural networks, summarising each book is like training a neural network to understand and represent each category meaningfully.
Doing this reduces the library’s vastness (or dimensionality) to just a set of keywords or summaries, making it easier to work with and draw insights from.
In essence, embeddings help us take something vast and complex (like the content of a book) and represent it in a simpler, more digestible format.
OK, hopefully you are still with me! 🙂
Embeddings in Practice
So, how do embeddings help us? Here is an example of shallow embedding (ie simple).
Say I have three words:
- apple
- pear
- hammer
I then convert all of these into embeddings. I then supply a fourth word to see if any of the above are similar. So let’s take “food” for example. Through some maths (cosine similarities, not important at this stage just for interest), we can determine which words are similar to “food” by comparing their vectors so that it would return “apple” and “pear”. Similarly, if I were to ask it for “fruit” I would get the same result but if I asked for “tool” I would only get the hammer back.
So now let’s imagine having a large number of documents in a business, Support documentation, Policy, Compliance etc and you wanted your team to be able to ask general questions about a topic, which this documentation covers, and get a meaningful “correct” answers back without having to trawl through every document… here enters embeddings.
The concept is exactly the same: we “chunk up” the documents, let’s say into 200-word blocks, and turn them into embeddings. Then, a team member can ask a question. We turn the question into an embedding and then find the “chunks” similar to the question.
Visualizing Embeddings
Because embeddings are vectors, we are able to visualise them. Below is such a visualisation:
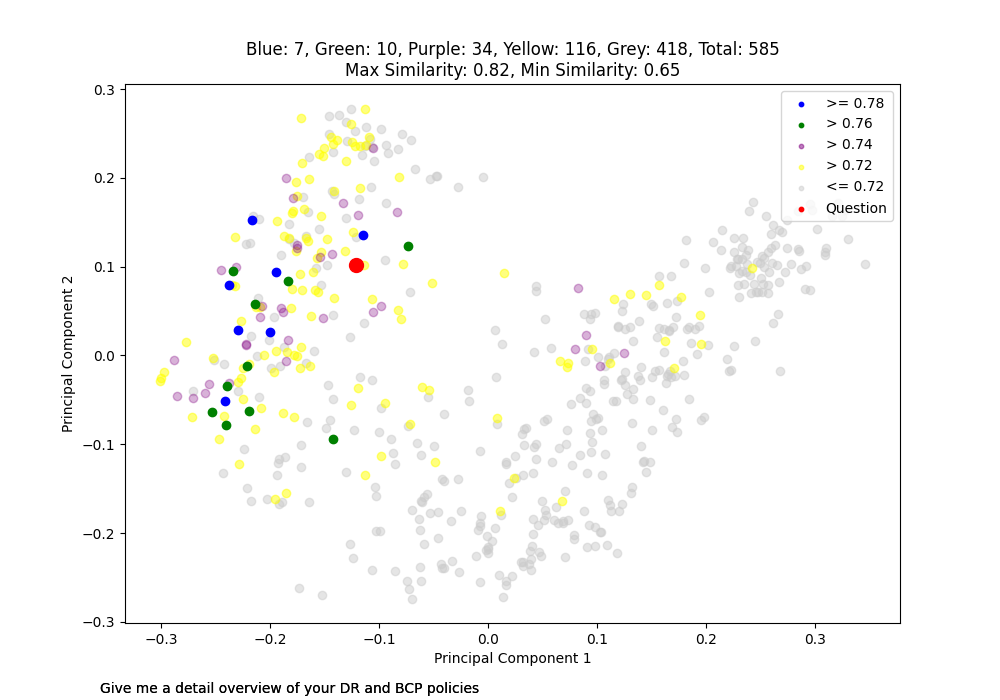
Each dot on the graph represents a single “chunk” (200 words) of embedding data. The question was “Give me a detailed overview of your DR and BCP policies”. The RED dot indicates the question embedding. The BLUE dots represent the closet similar chunks to my question related to.
Now sit and soak in that for a second …
What this means is you can have people ask a question and get the “correct” answer back! Now, I can hear the questions flying in, “they are just chunks of info” and “they aren’t useful in that form”!
If that were it, you would be correct.
So, what has been released in the last 6-12 months that has been the catalyst for so much innovation? Large Language Models, GPT in particular.
OpenAI has a very easy-to-use Embedding API endpoint to help you with embedding. You can then use GPT-4 to formulate a response.
A Glimpse into the Technical Side
So, to finish up, here is a basic prompt I have been playing with that has helped format the response from GPT-4.
Here is the response:

I’d like to learn how to use AI to improve RedEye user manuals.
Hey Julia, my advice is to have a good play with ChatGPT to start with. The important thing is to remember it’s just a tool, so be clear what you want to improve, is it language, do you want to intro “flare” or readability etc. You might even want to get it to rewrite it in pirate speak. 🙂