

In my last post, I delved into the theory and tried to demystify embedding and how it might be used in a practice sense. Today, we will go deeper and get more practical with the learnings I have gained over the last few weeks.
Let’s set some context first. My goal was to create an integrated “chatbot” prototype for my current organisation and help surface organisational information through the use of GPT and prompting.
The “backend” of this solution was a single database, which happens to be embedded data.
So, what is an embedded database?
Simply put, an embed database stores numerical vectors representing words or phrases (if this doesn’t make sense, then pop over to my first post). Each record is a chunk of information from documents from the organisation (50 words in each chunk) that is then converted to its numerical vector form. In my original design, I had all different types of information in one database. Topics such as Support, Compliance, Security, Tender information etc.
The virtue of segregation
In hindsight, and probably obvious, storing all the information in a single database and using this to respond to questions was ultimately flawed. The reason why is in what problem are we trying to solve with this solution? Are we trying to get creative/dynamic output, or are we trying to get factually accurate answers to business questions? Of course, it is the latter.
So, why is this separation of the data important? Because we have to understand how GPT works. It takes the information we send it and then tries to use it as input to generate a cohesive response, BUT what GPT doesn’t have (unless you bake it in somehow) is the context of the information it uses.
If we have a single source that is used to gather information to answer a question, and those sources of information come from diverse categories, it is possible (and I have seen it) to get “Information Bleed”, where by, you retrieve chunks of information from the embed database which could be seen as slightly related (or “similar” in terms of comparing vectors) BUT with difference contexts.
Containing the Bleed
As stated before, Information bleed occurs when data from one category seeps into another, muddying the waters and potentially leading to inaccurate or irrelevant responses from GPT. By segregating embeddings into distinct databases based on their categories or domains, we create well-defined, organised compartments of knowledge. This segregation acts as a protection against information bleed. This could be solved in other ways; this was just one approach.
Drawing Boundaries, Wisely
However, it’s pivotal to strike a balance. Over-segregation could lead to siloed information, impeding the unearthing of valuable cross-domain insights. The key is to delineate categories wisely, ensuring they are logical, meaningful, and beneficial to the task. We could “hard code” a process where the user could specify the types of information they wanted, and then the searching process could use that to filter out any extraneous information that isn’t useful.
I wanted to experiment with something a little more dynamic. Here, enters GPT as a question classifier.
Using GPT as a question classifier
As it stands today, I have three different categories of questions:
- Support
- Compliance
- Internal
I then have corresponding embed databases storing domain-specific information:
- support_embed.csv
- compliance_embed.csv
- internal_embed.csv
The first step is to determine what type of question is being asked. So, for instance, if the question is something like “How do I use and get benefit from <enter product name>?” then I want GPT to evaluate the question and make a call on what it thinks it might be.
Here is the prompt that I am using to achieve this currently:
Classify the following question into categories of support, compliance, and/or internal.
Your response must be in a Python array.
Your response should be in lowercase.
Only respond with one of each category.
When I send this question to gpt-3.5, I get the following response:
[ ‘support’ ]
“Your response must be in a Python array.” helps me return the information in a format I can use programmatically. You could do this in code, but I wanted to see if I could get GPT to consistently return the right result in the right format, which it currently does.
So, what does my code look like to achieve this? Here is one I prepared earlier (in python). 🙂
def determine_question_type(question):
system_content = '''
Classify the following question into categories of support, compliance, and/or internal.
Your response must be in a Python array.
Your response should be in lowercase.
Only respond with one of each category.
'''
model = "gpt-3.5-turbo"
response = openai.ChatCompletion.create(
model=model,
messages=[
{"role": "system", "content": system_content},
{"role": "user", "content": question}
],
temperature=0.1
)
response_str = response.choices[0].message["content"].strip()
# Validate and convert the response to a Python array
try:
return literal_eval(response_str)
except ValueError:
print("The model's response could not be converted to a Python array.")
return None
My main concern with this is what if the output fails and isn’t returned in the right format? Like most coding, we look to test automation to help with this. There is an interesting topic here, which is called Prompt Drift, and is something that will need to be considered when using Large Language Models for automation of processes.
What is prompt drift?
Prompt drift refers to a situation in large language models where the model gradually veers away from the original intent of the prompt over a series of generations or interactions. It’s akin to playing a game of telephone, where the message morphs as it passes from person to person, often ending up as a comical or nonsensical version of the original.
Here are some “manual” ideas on how to tackle this:
- Prompt Refinement:
- Make your prompts more explicit and detailed to guide the model towards the desired direction.
- Temperature Tuning:
- Adjusting the “temperature” of the model, a parameter that controls randomness, can help. Lower temperature values like 0.1 or 0.2 make the model’s output more focused and conservative, reducing drift.
- Token Limitation:
- Limit the number of tokens (words or characters) generated in each iteration to maintain tighter control over the narrative.
- Utilising Contextual Information:
- Including contextual cues or additional information in the prompt can help the model maintain adherence to the original topic.
Another method that I have been made aware of is “evals.” this is where you have several versions of your prompt; you specify the model you are using and how many tokens, then give several inputs and evaluate the output, hence its name.
Below is a real-world example of where I refined my question classifier prompt. “chosen” means that the response from GPT was correct, and “not chosen” is incorrect.
As you can see from the image below, I started at 50% accuracy and, with some refinement, got to 60%, then the latter is currently 100% accurate (from the samples).
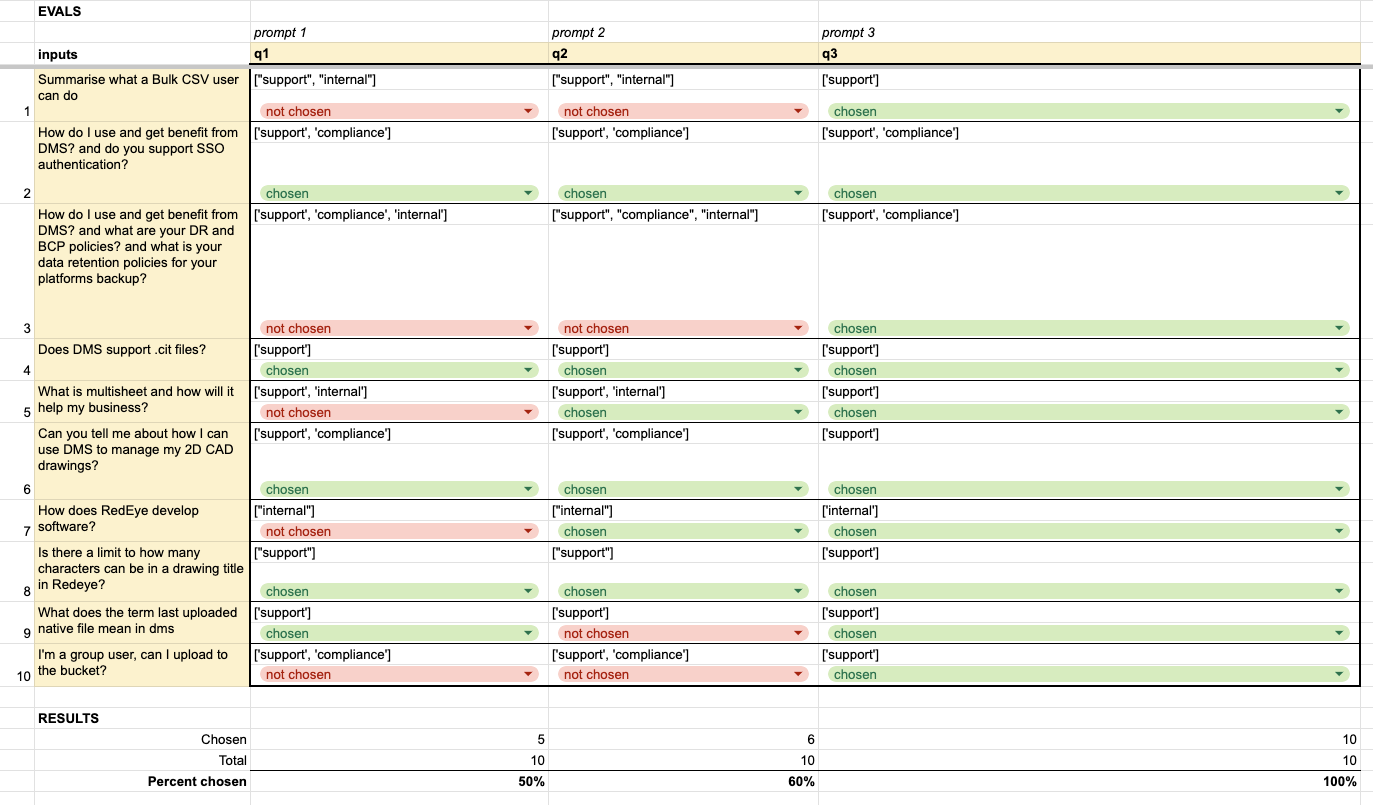
(NB: I am using a Google Sheet extension that does the OpenAI GPT calls in real-time, so as you change the inputs, the output changes)
So, the newly refined question classifier prompt went from:
Classify the following question into categories of support, compliance, and/or internal.
Your response must be in a Python array.
Your response should be in lowercase.
Only respond with one of each category.
Classify the following question into categories of support, compliance, and/or internal.Your response must always be in a Python array.Your response should be in lowercase.DO NOT repeat classifications.Here are some guidelines for classifying:Upload is a support term.Internal topics include, ways of working, software development lifecycle and integrations.When asking about functionality SSO is support, otherwise it is compliance.
That’s a wrap … for now. 🙂
So, that’s a wrap on my journey into the world of embedding and the potential of GPT for use as a question classifier and a search and response mechanism! Now, I am not suggesting you build your own; heaps of emerging products can do something similar. This exercise has given me a deep appreciation and understanding of how all the parts hang together and where the current limitations and challenges are.
For interest, Amazon has just released their Bedrock product, a load of foundational models you can deploy into your own environment. Very soon, they will release “agents”, enabling you to achieve what I have been working on mostly out of the box.
Stay tuned for my next post on the world of AI, especially how to operationalise it beyond just the technology parts of a business.
Recent Comments